
A lot of IT leaders think they have a supply chain problem when a shipment stalls, a supplier misses a date, or a key component goes unavailable. In practice, the break often shows up later. The refresh is approved, the racks need to come out, the laptops need to be retired, the storage arrays still hold regulated data, and suddenly the last step becomes the bottleneck.
That's a familiar failure pattern in data centers and distributed enterprise environments. The operational plan looks solid until the organization has to move, sanitize, document, transport, and disposition aging equipment under deadline. If that final link is weak, a routine refresh can turn into a continuity issue, a security issue, and a governance issue at the same time. A useful primer on the end-of-life process is this overview of IT asset disposition.
The broader context matters. Around 75% of companies worldwide experienced supply chain disruptions in 2022, up from 48% in 2021, and 94% of Fortune 1000 companies reported disruptions, according to supply chain resilience statistics compiled by WiFiTalents. That doesn't just affect inbound freight. It affects reverse logistics, hardware recovery, e-waste handling, and the ability to close out decommissioning work without exposing the business.
Introduction When the Chain Breaks at the Final Link
An IT manager usually doesn't get warned that the failure is about to come from the retirement queue. It starts with a business event. A lease expiration. A merger. A cloud migration that moves faster than expected. A security team that wants older endpoints gone now, not next quarter.
Then the questions pile up.
Where the bottleneck actually shows up
The servers are still in place. The drives still contain sensitive data. The facilities team wants floor space back. Procurement wants asset counts reconciled. Legal wants records. Finance wants value recovery where possible. If the organization is relying on ad hoc pickup arrangements, scattered recyclers, or manual chain-of-custody logs, the end-of-life process slows everything around it.
That's why supply chain resilience can't be limited to sourcing and transportation. It has to include the controlled exit of assets from the environment.
The weakest control point in a technology supply chain is often the handoff no one treated as strategic.
Why this matters to business continuity
When retired hardware sits too long, teams create workarounds. Equipment gets staged in unsecured rooms. Project managers split pickups across vendors. Drives wait for destruction approvals. Audit trails become patchy. None of that looks dramatic in the moment, but it introduces delay and risk exactly when the organization needs clean execution.
A resilient operation handles disposal the same way it handles procurement. With defined ownership, documented process, approved vendors, and contingency paths when normal operations get disrupted.
Defining Modern Supply Chain Resilience
Supply chain resilience isn't just risk avoidance. It's the operating ability to anticipate, absorb, adapt, and recover when conditions change faster than the original plan.
Traditional risk management often focuses on known threats. A resilient model assumes some disruptions won't arrive in familiar form. It builds enough visibility, flexibility, and decision speed to keep operations moving anyway. That distinction matters in IT environments because hardware refresh, decommissioning, data destruction, and downstream recycling rarely fail in exactly the same way twice.
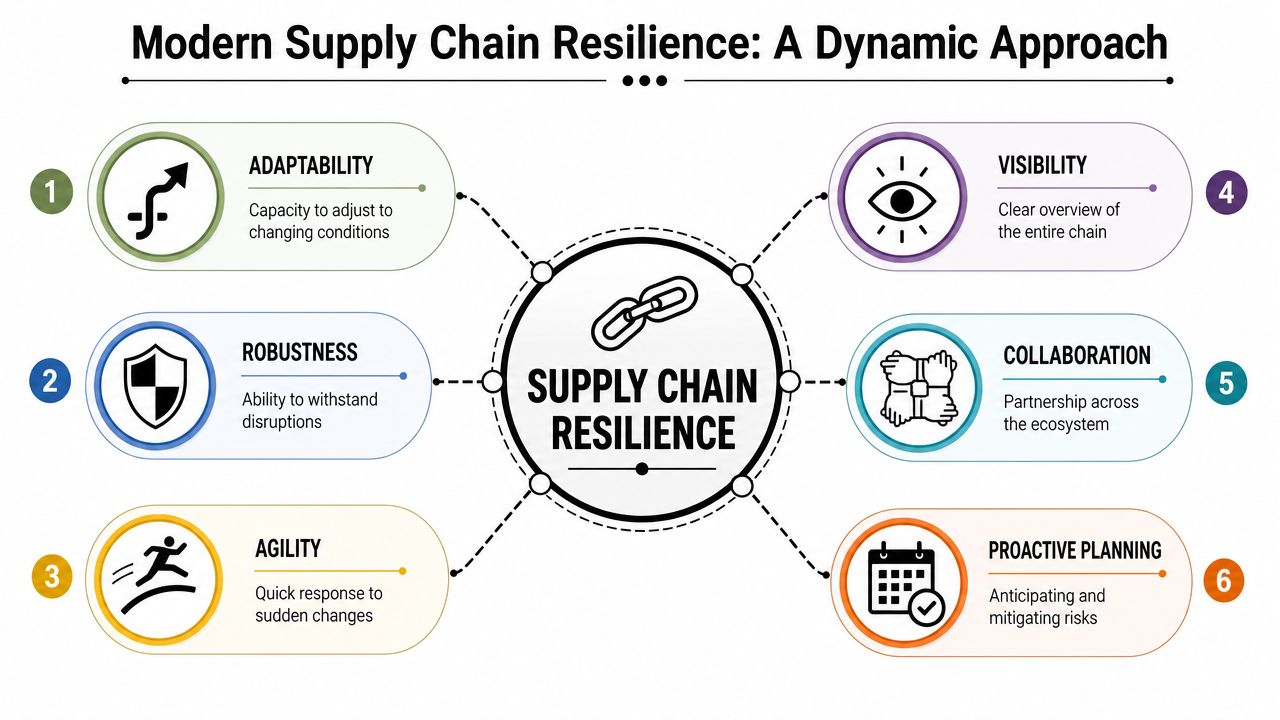
What resilience is and what it isn't
A simple way to separate the concepts is this:
| Approach | Primary focus | Typical weakness |
|---|---|---|
| Basic risk control | Prevent a known failure | Misses novel combinations of failures |
| Disaster recovery | Restore after a major event | Can be too narrow or too late |
| Supply chain resilience | Keep adapting before, during, and after disruption | Requires cross-functional discipline |
An athlete is a better analogy than a helmet. A helmet protects against one kind of impact. Training builds strength, stamina, and flexibility for whatever the competition delivers. Mature organizations treat supply chains the same way.
What that means for IT teams
For IT and facilities leaders, resilience means the asset lifecycle is managed as one connected system. Procurement, deployment, maintenance, redeployment, storage, and retirement should share the same control logic.
That's the practical value of IT asset lifecycle management. It gives teams one operating model instead of disconnected handoffs between procurement, infrastructure, security, and disposal vendors.
Resilience is less about predicting the exact disruption and more about making sure your process doesn't collapse when the disruption arrives.
Today's Threats and Hidden Failure Modes
Most supply chain discussions stop at obvious shocks. Supplier failure. Trade friction. Severe weather. Port congestion. Cyberattacks on logistics systems. Those threats are real, but the business impact becomes more concrete when you tie them to cash flow and execution.
Global supply chain disruptions in 2024 cost companies roughly 8% of their annual revenue on average, according to Procurement Tactics' 2025 analysis of supply chain statistics. That's not an abstract operations problem. It's a board-level performance issue.

The threats people see
Teams usually plan around visible external events:
- Geopolitical shocks that alter sourcing routes or supplier availability
- Climate-related disruption that affects transport lanes, sites, and utilities
- Cyber incidents that interrupt scheduling, warehouse, or shipment systems
- Supplier distress that reduces capacity when demand is already tight
Those belong in the model. They just aren't the whole model.
The failure modes people miss
The more costly problems often come from compound failures. One delayed pickup can block a decommissioning schedule. One missing serial reconciliation can delay closeout. One untracked drive can force legal review. One recycler with weak downstream capacity can create a pileup of retired equipment when the business expected a clean cutover.
That's why fault-path thinking helps. If your team hasn't used structured failure mapping before, Forge Reliability's FTA examples are a useful reference for breaking a large event into the smaller conditions that caused it.
Why hidden failure modes matter in IT environments
In IT, the issue isn't just that something goes wrong. It's that multiple groups depend on the same retirement event. Security wants verified destruction. Facilities wants removal. Finance wants asset records. Procurement wants vendor performance. If one part fails, the rest of the program slows or stops.
A related concern is that disruptions don't stay physical. Operational weakness at retirement can become a security exposure, especially where retired infrastructure still contains credentials, regulated data, or internal configuration details. That's why end-of-life planning belongs in broader cyber risk reviews, alongside resources on cybersecurity threats targeting Atlanta companies.
Frameworks and KPIs for Building Resilience
Resilience programs fail when they stay philosophical. The work gets real when leaders define operating pillars, assign ownership, and track a small set of metrics that influence decisions.
Research published through PMC on supply chain resilience strategies emphasizes that combining inventory-related mitigation with redundancy and flexibility, including pre-positioning inventory, maintaining reserves, and using multiple sourcing, creates a cost-effective framework. The lesson for IT teams is straightforward. Don't rely on one route, one processor, one buyer, or one downstream outlet for end-of-life equipment.
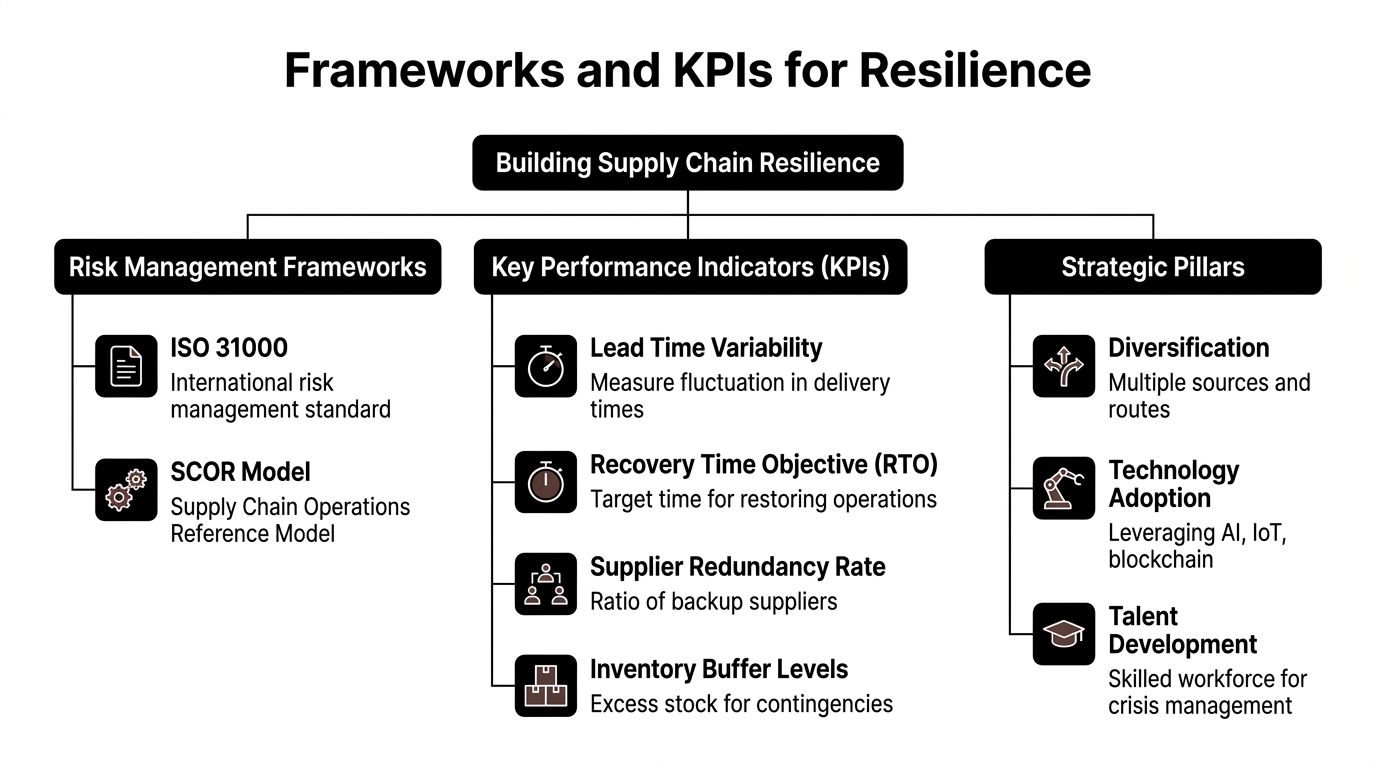
The pillars that hold up in practice
Three pillars usually make the difference:
Visibility
Know what assets you have, where they are, what data they hold, and what state they're in. If the retirement queue is managed in spreadsheets and inboxes, the process will break under pressure.
Flexibility
Maintain alternate paths. That can mean backup transportation, preapproved destruction methods, secondary processing options, or alternate staging plans when a site can't release equipment on the original timeline.
Redundancy
Some redundancy is waste. Strategic redundancy is insurance. For ITAD programs, that may mean maintaining more than one qualified downstream partner or preserving short-term buffer capacity during large refreshes.
Practical rule: If your process depends on one person, one vendor, or one facility always being available, it isn't resilient yet.
The KPIs worth tracking
Not every metric is useful. Focus on the ones that change decisions.
- Time to recover: How long it takes to restore the process after a disruption
- Chain-of-custody completeness: Whether every move is documented from pickup through final disposition
- Asset aging in retirement status: How long equipment sits after approval for removal
- Exception rate: How often serial counts, pickup records, or destruction documentation require rework
- Supplier backup readiness: Whether alternates are approved before they're needed
A strong review cadence matters too. Many organizations run vendor selection once and treat the file as complete. It isn't. A smarter approach is periodic vendor due diligence checklist reviews tied to security, logistics, and compliance stakeholders.
The Overlooked Resilience Gap in Your Data Center
Most resilience frameworks still concentrate on the front end. They map suppliers, transportation lanes, production sites, and inventory nodes. That's useful, but it leaves out a major operational choke point for modern enterprises: end-of-life technology infrastructure.
For many organizations, decommissioned servers, old data centers, and retired networking gear represent hidden single points of failure in continuity, security, and compliance, and authoritative frameworks often don't integrate end-of-life ITAD strategy into core resilience planning, as discussed in BCG's work on building resilience strategies.
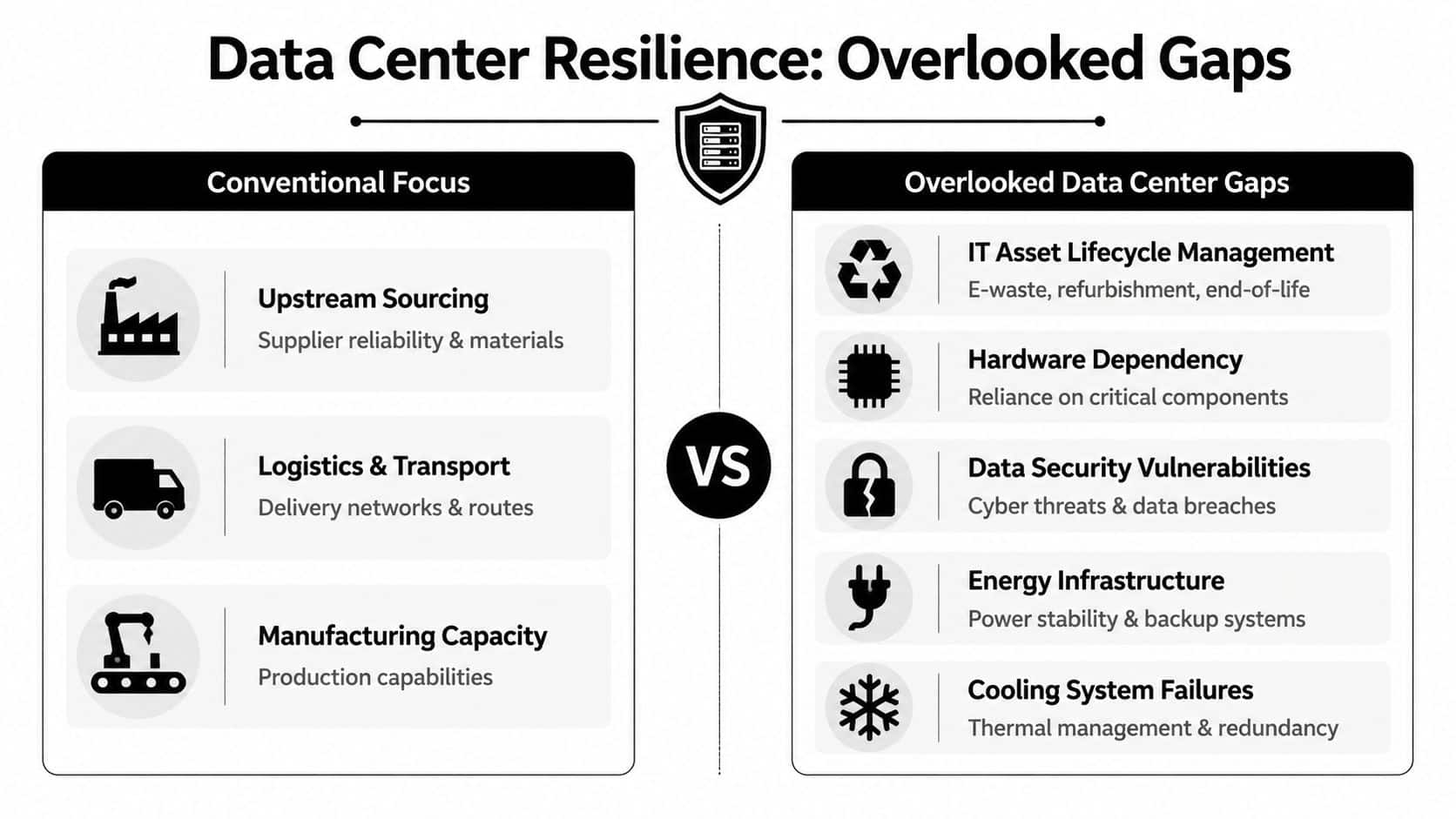
Why the blind spot persists
Many executive teams still classify ITAD as cleanup work. It gets delegated late, budgeted thinly, and measured only by whether the old gear left the building. That's too narrow.
A poorly run decommissioning effort can trigger several business problems at once:
- Security exposure: Drives and devices leave custody without consistent sanitization evidence
- Compliance weakness: Records don't support audit, disposal-rule, or governance requirements
- Project delay: New deployments wait while old assets remain in place
- Financial leakage: Reusable assets miss remarketing windows or lose recoverable value
What a data center team actually sees
In real-world environments, the friction shows up in the details. Mixed asset classes on the same pickup. Incomplete rack inventories. Contractors removing hardware before records are finalized. Legacy gear with uncertain ownership. Branch locations storing equipment far longer than policy allows.
That's why data center ITAD should sit inside resilience planning, not outside it. The issue isn't whether a recycler can haul equipment away. The issue is whether the organization can retire infrastructure without disrupting security controls, project schedules, or governance obligations.
If an enterprise can't remove old infrastructure cleanly, it doesn't have full control of its technology environment.
A Resilience Roadmap for IT Asset Disposition
Once teams recognize ITAD as a resilience function, the roadmap becomes clearer. The work falls into three connected disciplines: security, compliance, and logistics. If one of those is weak, the program becomes fragile.
Research summarized by American Public University on supply chain resilience indicates that firms with full or near-full visibility can reduce disruption recovery time by roughly 30% to 40% compared with those using fragmented or manual reporting. In ITAD, that matters because chain-of-custody control often fails first when the process isn't visible.
Secure the asset before you move the asset
Start with data-bearing equipment. Drives, arrays, laptops, mobile devices, backup media, and embedded storage need an approved destruction or wiping standard before removal begins. Don't let field decisions substitute for policy.
Build the process around documented controls:
- Approved methods: Define when to wipe, when to shred, and who authorizes exceptions
- Asset classification: Separate data-bearing from non-data-bearing equipment before logistics starts
- Evidence retention: Keep serial-level and destruction records where audit, legal, and security teams can access them
Secure disposition is a governance control, not just an operations task.
Treat documentation as an operating requirement
Many disruptions become serious because records lag behind physical movement. If the pickup happened but the custody record didn't, your governance position is weaker than you think.
A defensible program includes:
- intake and inventory validation,
- chain-of-custody documentation at each transfer point,
- documented destruction or processing outcome,
- reconciliation back to the approved asset list.
Choose partners for stress conditions, not only normal conditions
A vendor may perform well on an easy pickup and fail during a large move, a multi-site refresh, or a compressed decommissioning window. Evaluate partner capability under pressure.
Ask practical questions. Can they support nationwide coordination? Can they segregate regulated assets? Can they handle on-site and off-site workflows? Can they produce clean reporting when a schedule changes mid-project? Can they keep processing moving when one downstream outlet tightens capacity?
What works is boring in the best sense. Preapproved workflows. Clear escalation paths. Scheduled audits. Contingency routing. Strong records. What doesn't work is improvisation disguised as flexibility.
Building True Continuity from Beginning to End
A narrow resilience strategy leaves a predictable weakness. The business invests in supplier diversification, inventory planning, and transport visibility, then treats end-of-life hardware as an afterthought. That split doesn't hold up once an office closes, a data center exits, a merger compresses timelines, or a security initiative accelerates refresh cycles.
True supply chain resilience runs across the full asset lifecycle. It starts with sourcing, continues through deployment and maintenance, and finishes with secure, documented disposition. That final stage isn't housekeeping. It's where continuity, compliance, security, and value recovery either stay aligned or come apart.
The practical standard
A resilient organization can answer a few hard questions without scrambling:
| Question | Strong answer |
|---|---|
| Do we know what equipment is leaving? | Yes, with validated inventory records |
| Do we know what data risk it carries? | Yes, by asset class and sanitization method |
| Do we know who handled it? | Yes, through documented custody |
| Can the process keep moving under disruption? | Yes, with alternate logistics and processing paths |
That's the standard worth building toward. It's defensible in audits, useful in projects, and far less expensive than cleaning up the consequences of a weak retirement process.
The companies that handle this well don't think of retired electronics as waste first. They treat them as controlled assets until the final documented disposition event is complete.
For organizations that need a stronger end-to-end approach, Beyond Surplus helps businesses manage certified electronics recycling, secure data destruction, IT equipment disposal, product destruction, and data center decommissioning with documented chain of custody and nationwide pickup support. Contact Beyond Surplus for certified electronics recycling and secure IT asset disposal.



